
基本的な統計量による分析手法
基本統計量は、データの特徴を示す中心傾向やばらつきを理解するための手法です。

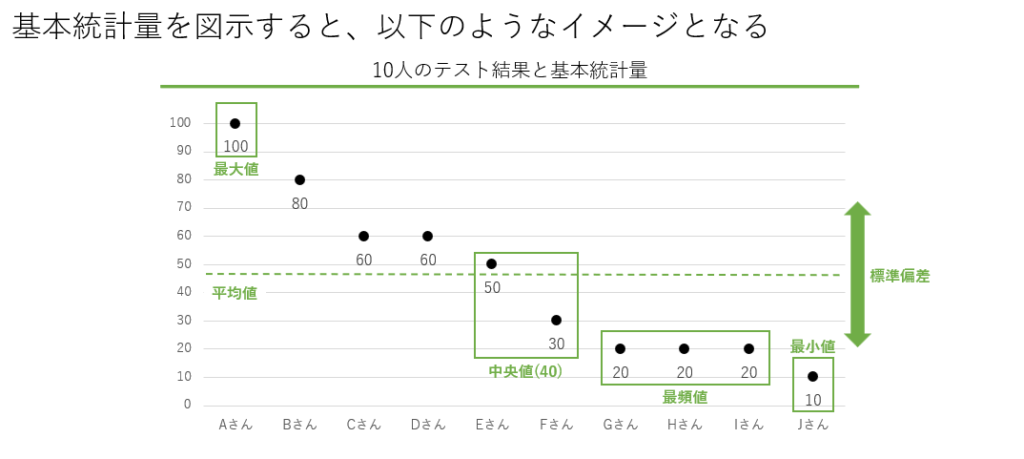
平均値・中央値・最頻値・最大値・最小値
これらは最も基本的な統計量で、データの中心的な傾向や範囲を理解するために使われます。
平均値
平均値はデータの総和をデータの個数で割ったもので、全体の傾向を一つの数字で表します。例えば、学生のテストの点数を分析する際に平均点を求めることで、クラス全体の学力レベルを把握できます。
中央値
中央値はデータを昇順または降順に並べた際の中央の値です。外れ値の影響を受けにくい特性があるため、データのばらつきが大きい場合に有用です。例えば、住宅価格の分析においては、極端に高い価格や低い価格が存在することが多いため、中央値を使用することで一般的な価格帯を把握しやすくなります。
最頻値
最頻値はデータの中で最も頻繁に出現する値です。これはカテゴリカルデータの分析において特に有用で、どのカテゴリが最も一般的であるかを示します。例えば、マーケットリサーチで顧客の購入頻度を分析する際に、最も購入される商品を特定するために使用できます。
最大値・最小値
最大値と最小値はそれぞれデータの中で最も大きい値と最も小さい値を示します。これらの値はデータの範囲を理解するために重要です。例えば、製品の品質管理において、製品のサイズのばらつきを確認するために最大値と最小値を使用します。また、外れ値を把握する手助けもします。
分散・標準偏差
分散と標準偏差は、データのばらつきを示す統計的指標です。どちらもデータがどれだけ平均から離れているかを示しますが、それぞれに異なる特徴とメリットがあります。
分散
分散は、各データポイントが平均からどれだけ離れているかを平方して平均した値です。計算方法としては、まず各データポイントと平均値との差を求め、その差を二乗します。次に、その二乗した値の平均を計算します。分散はデータのばらつきを示すための基本的な指標であり、特に大きなばらつきを強調する特徴があります。
標準偏差
標準偏差は、分散の平方根を取った値です。分散は二乗された単位で表されるため、元のデータと同じ単位でばらつきを理解するために標準偏差が用いられます。標準偏差は直感的に理解しやすく、データの広がりを元の単位で表現するため、実用的な解釈が容易です。
データの可視化
データの可視化は、数値データをグラフや図表で表現することで、パターンや傾向を直感的に理解する手助けをします。
グラフ
円グラフはデータの割合を視覚的に示すのに適しており、カテゴリごとの構成比を直感的に理解できます。棒グラフはカテゴリカルデータの比較に適しており、各カテゴリの値を視覚的に比較できます。折れ線グラフは時系列データの変化を示すのに適しており、データの傾向を追いやすくなります。
散布図
散布図は2つの変数間の関係を視覚的に示すグラフです。データポイントがどのように分布しているかを見ることで、変数間の相関関係を把握できます。例えば、広告費と売上の関係を分析する際に散布図を用いることで、広告費の増加に伴う売上の増減を視覚的に確認できます。
ヒストグラム
ヒストグラムはデータの分布を視覚的に示すグラフで、データを一定の範囲に分けて頻度を表示します。データの偏りや集中度を理解するのに役立ちます。例えば、顧客の購入金額を分析する際にヒストグラムを用いることで、特定の価格帯に顧客が集中しているかどうかを把握できます。
箱ひげ図
箱ひげ図はデータの分布を示す視覚的なツールで、中央値や四分位数を含むデータの要約を提供します。データのばらつきや外れ値を簡単に確認できるため、品質管理や異常検知に役立ちます。例えば、製品のテスト結果を箱ひげ図で表示することで、異常なテスト結果を迅速に特定できます。
四分位数
四分位数はデータを4つの等しい部分に分ける値で、データのばらつきや異常値を理解するのに役立ちます。四分位数を用いることで、データの中心傾向と広がりを簡単に把握できます。例えば、社員の給与データを四分位数で分析することで、給与の分布や異常値を評価できます。
クロス集計
クロス集計は2つ以上のカテゴリ変数の関係を分析するための手法で、データの分布を理解するのに役立ちます。マーケティングや顧客分析において、異なるカテゴリ間の相関を把握するために広く使用されます。例えば、性別と購買行動の関係を分析する際にクロス集計を用いることで、特定の性別が特定の商品を好む傾向を明らかにできます。
統計的検定
統計的検定は、データ分析において仮説を検証するための重要な手法です。得られたデータが偶然の結果ではなく、実際に意味があるかどうかを判断するために使用されます。
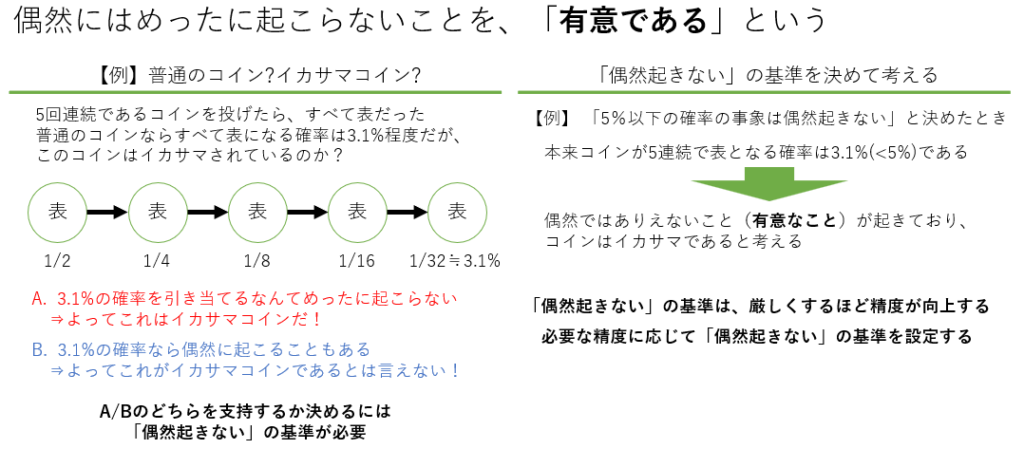
t検定
t検定は、2つの平均値の間に差があるかどうかを検証するための統計手法です。一般的に、標本の平均値が母集団の平均値と異なるかどうかを確認するために使用されます。t検定には、以下の2つの主要なタイプがあります。
- 対応のあるt検定(ペアt検定): 同じグループの異なる条件(例: 時間の前後)における平均値の差を検証する場合に使用されます。
- 対応のないt検定(独立t検定): 異なるグループ間の平均値の差を検証する場合に使用されます。
t検定では、検定統計量(t値)と自由度に基づいて、帰無仮説(例えば「両平均は等しい」)を棄却するかどうかを決定します。
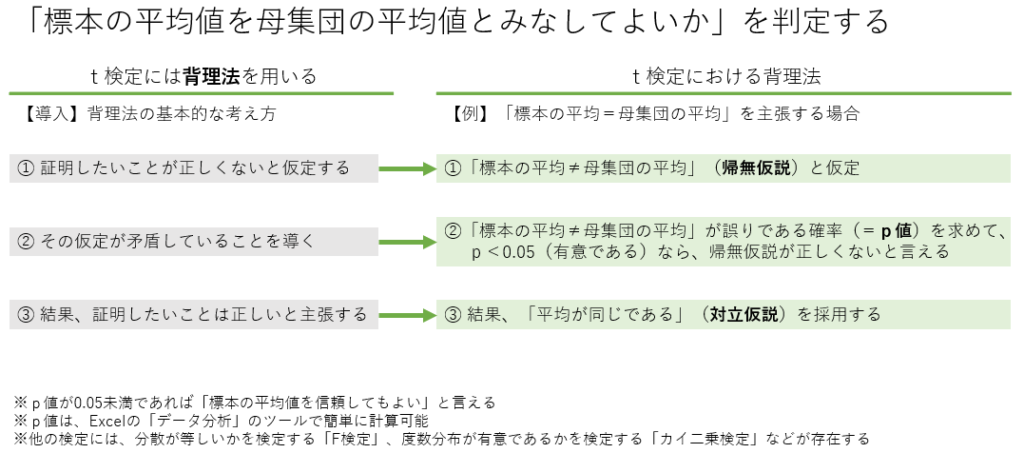
F検定
F検定は、複数の群の分散が等しいかどうかを検証するための統計手法です。通常、分散の比較や回帰分析において使用されます。F検定では、F値という検定統計量を計算し、それが一定の有意水準を超えるかどうかで帰無仮説を検証します。
例えば、2つ以上のグループの平均値を比較する場合や、モデルの適合度を評価する際に利用されることがあります。
カイ二乗検定
カイ二乗検定は、観測度数と期待度数の間の適合度を検証するための統計手法です。カテゴリカルデータ(例: クロス集計表)の分析に使用され、観測されたデータが期待される分布とどれだけ異なるかを確認します。
カイ二乗値が大きいほど、観測されたデータと期待されるデータの間に有意な違いがあることを示し、帰無仮説を棄却します。
基本的なデータ分析手法
ビジネス現場のデータ分析において、頻繁に活用される基本的なデータ分析手法です。
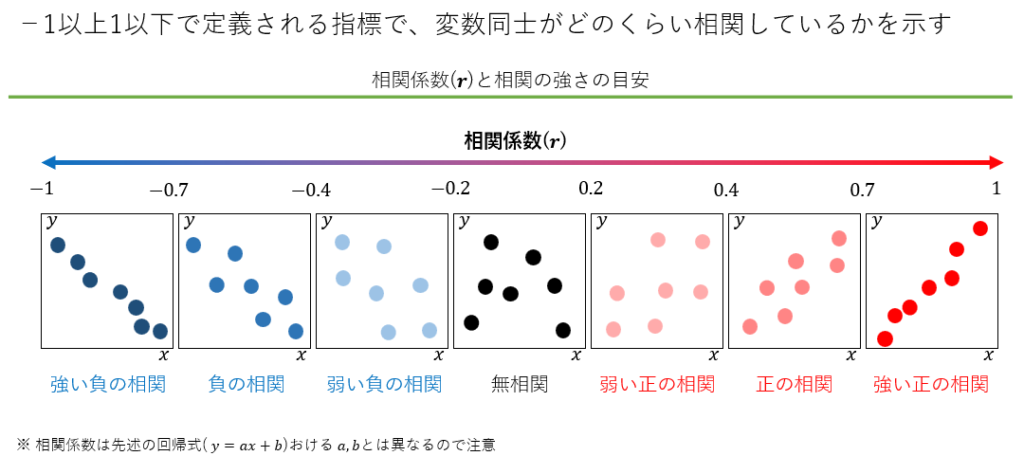
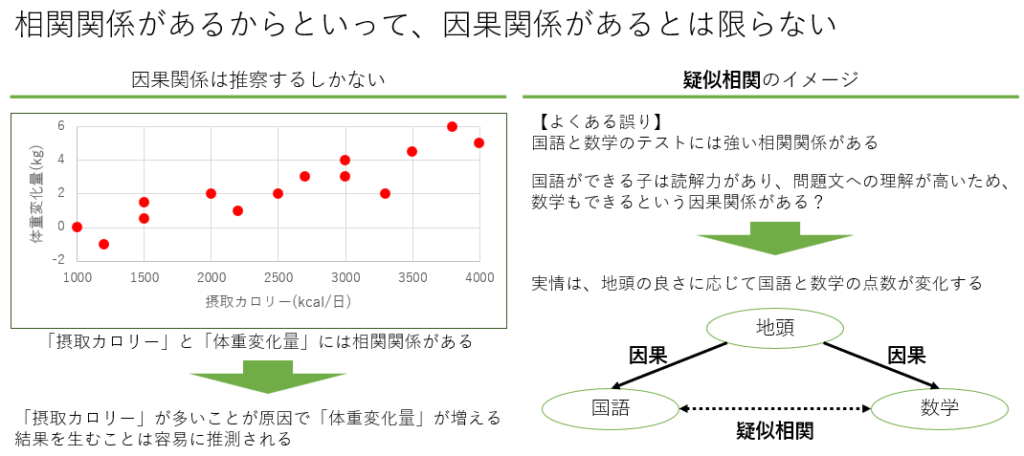
相関分析
相関分析は2つの変数間の関係の強さと方向を測定します。相関係数は-1から1の範囲で表され、1に近いほど強い正の相関、-1に近いほど強い負の相関を示します。例えば、気温とアイスクリームの売上の関係を分析する際に相関分析を用いることで、気温が上がると売上が増える傾向があるかどうかを確認できます。

回帰分析
回帰分析は1つの従属変数と1つ以上の独立変数の関係をモデル化する手法です。
単回帰分析
単回帰分析は1つの独立変数と1つの従属変数の関係をモデル化します。例えば、広告費と売上の関係を単回帰分析でモデル化することで、広告費が増加すると売上がどれだけ増加するかを予測できます。

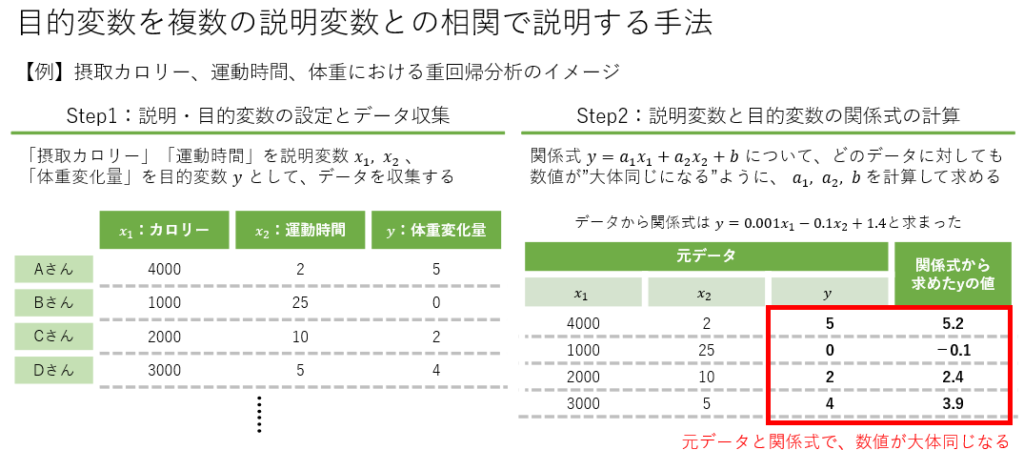
重回帰分析
重回帰分析は複数の独立変数と1つの従属変数の関係をモデル化します。例えば、広告費、プロモーション費、商品価格など複数の要因が売上に与える影響を同時に評価する際に重回帰分析を用います。

ダミー変数
ダミー変数はカテゴリカルデータを数値データに変換するために使われる手法で、回帰分析などで使用されます。例えば、性別や地域などのカテゴリデータを回帰分析に組み込む際に、ダミー変数を使用して数値化します。
時系列分析
時系列分析は時間とともに変化するデータを分析する手法です。例えば、売上データや株価データなど、時間の経過に伴って変動するデータの傾向やパターンを分析します。
移動平均
移動平均は過去のデータポイントの平均を計算し、データの傾向を平滑化します。例えば、月次売上データの移動平均を計算することで、季節的な変動を除いた売上のトレンドを把握できます。
季節要因
季節要因は周期的なパターンを識別し、データの予測に役立てます。例えば、季節ごとの売上の変動を分析することで、特定の時期に売上が増加するパターンを特定し、在庫管理やプロモーション戦略に活用できます。
応用的なデータ分析手法
より複雑なデータ解析やパターン発見に活用される機械学習手法を中心に紹介します。

教師あり学習
教師あり学習は既知のラベルが付いたデータを使用してモデルを訓練し、未知のデータに対して予測を行う手法です。
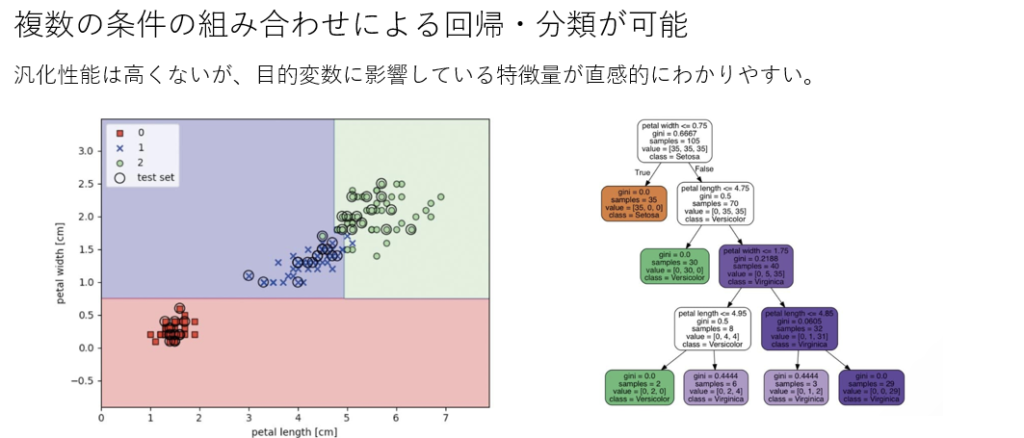
決定木
決定木はデータを特徴に基づいて分類するためのツリーベースの手法です。例えば、顧客の購買行動を分析して、特定の特徴を持つ顧客がどのような商品を購入する可能性が高いかを予測できます。
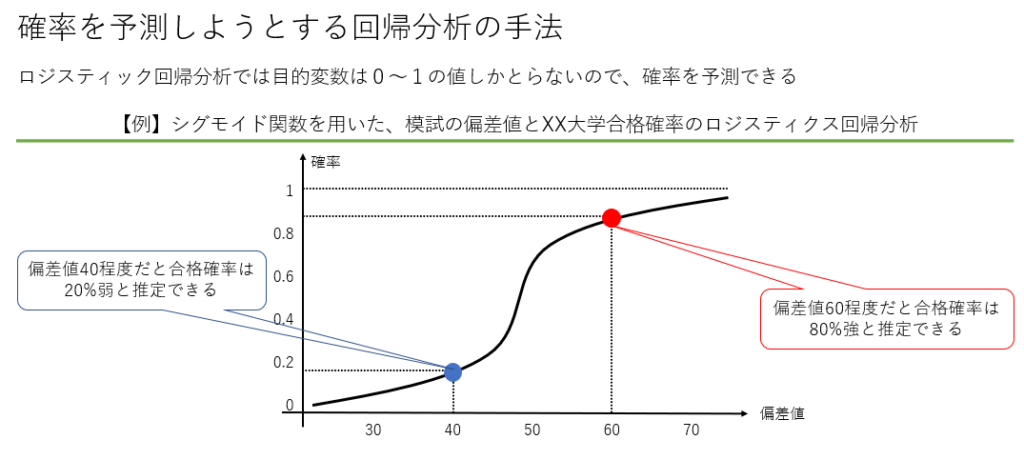
ロジスティック回帰
ロジスティック回帰は2値分類問題を解決するための回帰分析の一種です。例えば、顧客が特定のサービスを契約するかどうかを予測する際にロジスティック回帰を使用します。
SVM(サポートベクターマシン)
SVM(サポートベクターマシン)はデータを分類するための強力な線形モデルです。例えば、メールのスパムフィルタリングにおいて、メールがスパムかどうかを分類する際にSVMを使用します。

ランダムフォレスト
ランダムフォレストは複数の決定木を使用して予測精度を向上させる手法です。例えば、顧客の離脱予測において、複数の決定木を組み合わせて精度の高い予測を行います。
自己回帰モデル
自己回帰モデルは時間系列データの予測に使用されるモデルで、過去のデータを基に未来の値を予測します。例えば、株価の予測において、過去の株価データを使用して将来の株価を予測します。
教師なし学習
教師なし学習はラベルのないデータを使用してデータの構造やパターンを発見する手法です。
K平均法(K-means)
K平均法(K-means)はデータを指定した数のクラスタに分類する手法です。例えば、顧客の購買行動をクラスタリングすることで、類似した購買パターンを持つ顧客グループを特定できます。
主成分分析(PCA)
主成分分析(PCA)はデータの次元を削減し、データの構造を理解するための手法です。例えば、多次元のセンサーデータを主成分分析で次元削減し、主要なパターンを把握します。
アソシエーション分析
アソシエーション分析はアイテム間の関係を発見するための手法で、マーケットバスケット分析などに使用されます。例えば、スーパーの購買データを分析して、特定の商品が一緒に購入される頻度を特定します。
強化学習
強化学習はエージェントが環境と相互作用しながら最適な行動を学習する手法です。
Q学習
Q学習はエージェントが報酬を最大化するための行動を学習する手法で、ゲームやロボティクスなどで使用されます。例えば、ゲームのAIが最適な戦略を学習する際にQ学習を使用します。
高度なデータ分析手法と最新技術
最新のディープラーニングは、人の判断力のような振る舞いをし、さらには人では見落としがちなパターンを発見する能力を持っています。
ディープラーニング
ディープラーニングは複雑なパターンを学習するための多層構造を持つモデルで、大規模なデータセットを処理するのに適しています。
ニューラルネットワーク
ニューラルネットワークは人間の脳の構造を模倣したモデルで、複雑なデータのパターンを学習します。例えば、画像認識や音声認識において広く使用されます。
畳み込みニューラルネットワーク(CNN)
畳み込みニューラルネットワーク(CNN)は主に画像データの処理に使用されるネットワークで、画像の特徴を自動的に抽出します。例えば、物体検出や顔認識において高い性能を発揮します。
再帰型ニューラルネットワーク(RNN)
再帰型ニューラルネットワーク(RNN)は時系列データの処理に適したネットワークで、シーケンスデータのパターンを学習します。例えば、テキスト生成や音声認識において使用されます。
ディープQネットワーク(DQN)
ディープQネットワーク(DQN)は強化学習の一種で、ディープラーニングを用いてQ学習を行います。例えば、ゲームの戦略学習において高い性能を発揮します。
生成モデル
生成モデルは、与えられたデータセットから新しいデータを生成するためのアルゴリズムです。画像生成、データ拡張、テキスト生成など、さまざまな応用が可能です。
生成敵対ネットワーク(GAN)
生成敵対ネットワーク(GAN)は、2つのニューラルネットワーク(生成器と識別器)が互いに競争することでデータを生成します。生成器は本物のように見えるデータを作り出し、識別器はそのデータが本物か偽物かを判断します。このプロセスを繰り返すことで、生成器は非常にリアルなデータを生成できるようになります。例えば、GANは写真のスタイル変換や新しいキャラクターの生成に使用されます。
変分オートエンコーダ(VAE)
変分オートエンコーダ(VAE)は、データの潜在的な特徴を学習し、新しいデータを生成するためのモデルです。VAEはデータの分布を学習し、その分布から新しいデータポイントをサンプリングすることで、生成プロセスを実現します。例えば、VAEは画像生成やデータの補完に使用されます。
ビッグデータ分析
ビッグデータ分析は大量のデータセットを処理し、洞察を得るための手法です。大規模なデータの中から有益な情報を抽出し、ビジネスや研究に活用します。例えば、ソーシャルメディアデータを分析して消費者の感情やトレンドを把握することができます。
テキストマイニング
テキストマイニングは、膨大な量のテキストデータから有益な情報を抽出し、ビジネスや研究に活用するための手法です。以下に主要な手法とその応用例を紹介します。
自然言語処理(NLP)
自然言語処理(NLP)は、テキストデータを解析し、言語の構造や意味を理解するための技術です。NLPはチャットボットの開発、自動翻訳、感情分析などで広く使用されています。チャットボットではユーザーとの自然な対話を、自動翻訳では異なる言語間の翻訳を行います。感情分析では、テキストデータからポジティブ、ネガティブ、ニュートラルな感情を抽出し、消費者の感情を理解するのに役立ちます。
トピックモデル
トピックモデルは文書集合から潜在的なトピックを抽出する手法で、Latent Dirichlet Allocation(LDA)などのアルゴリズムが使われます。例えば、ニュース記事を分析して、特定の期間中にどのようなトピックが話題になっているかを把握できます。これにより、大量の文書を効率的に整理し、重要なテーマや傾向を特定することができます。
固有表現抽出(NER)
固有表現抽出(NER)は、テキストから特定の実体(名前、場所、日時など)を抽出する手法です。例えば、ニュース記事から人名や地名を抽出して関連情報を整理することができます。これにより、重要な情報を迅速に特定し、データの整理や検索が容易になります。
分析手法の選び方と適用例
目的に応じて適切な手法を選ぶことが重要です。
データ分析手法を選ぶ際には、目的やデータの特性、リソースを考慮する必要があります。目的別に適した分析手法の例を示します。
回帰問題
回帰問題は、連続値の予測が必要な場合に適しています。例えば、住宅価格の予測では、過去の住宅販売データをもとに現在の市場価格を予測し、不動産取引の参考にします。売上予測では、過去の売上データや市場トレンドをもとに未来の売上を予測し、在庫管理やプロモーション戦略に役立てます。また、気温予測では、過去の気温データや気象条件をもとに未来の気温を予測し、農業やエネルギー管理に利用します。
回帰問題に適した手法には、線形回帰、重回帰分析、ニューラルネットワークなどが適用されます。
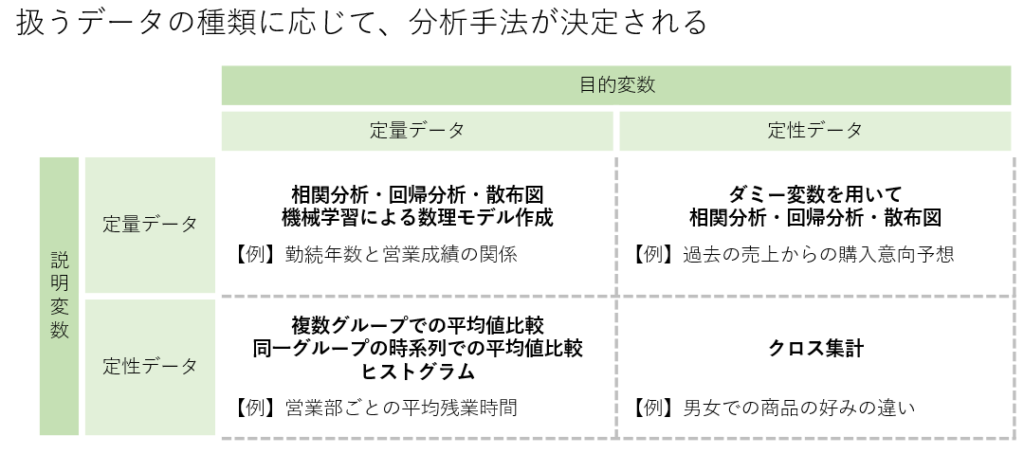
分類問題
分類問題は、データを複数のカテゴリに分類することを目的としています。例えば、スパムメールの分類では、メールがスパムかどうかを判断し、ユーザーの受信トレイを整理することができます。また、顧客行動の予測では、新規顧客が特定の商品を購入するかどうかを予測し、ターゲットマーケティングに活用します。病気の診断においては、患者の症状データをもとに病気の種類を特定し、適切な治療を行うためのサポートとなります。
分類問題に適した手法には、ロジスティック回帰、決定木、ランダムフォレスト、サポートベクターマシン(SVM)、ニューラルネットワークなどがあります。
クラスタリング
クラスタリングは、データを自然なグループに分けるための手法です。例えば、顧客セグメンテーションでは、顧客の購買行動や属性データをもとに似た特性を持つ顧客グループを特定し、ターゲットマーケティングやカスタマイズされたサービス提供に役立てます。市場調査では、消費者の嗜好や行動を分析し、類似したグループに分けることで、新製品の開発やマーケティング戦略の立案に利用します。
クラスタリングに適した手法には、K平均法(K-means)、階層的クラスタリングなどがあります。
時系列予測
時系列予測は、過去のデータに基づいて未来の値を予測する手法です。例えば、売上の予測では、過去の売上データをもとに未来の売上を予測し、在庫管理や予算計画に役立てます。株価の予測では、過去の株価データをもとに未来の株価を予測し、投資戦略の立案に利用します。また、需要予測では、過去の需要データをもとに未来の需要を予測し、サプライチェーン管理に役立てます。
時系列予測に適した手法には、自己回帰モデル、移動平均モデル、季節要因の分析などが適用されます。
異常検知
異常検知は、データセット内の異常なパターンを検出する手法です。例えば、クレジットカードの不正使用検出では、異常な取引パターンを検出して不正行為を防ぎます。機械の故障予知では、センサーデータをもとに異常な動作を検出し、故障を予防します。ネットワークセキュリティでは、異常なトラフィックを検出してサイバー攻撃を防ぎます。
異常検知に適した手法には、サポートベクターマシンや外れ値の分析などがあります。
まとめ
この記事では、データ分析の手法を基本から高度な技術まで体系的に紹介しました。
- 基本統計量による分析:基本統計量には、平均値、中央値、最頻値、最大値、最小値があります。これらはデータの中心的な傾向や範囲を把握するための基本的な指標です。分散と標準偏差は、データのばらつきを示す統計的指標で、データがどれだけ平均から離れているかを理解するのに重要です。統計的検定は、データ間の差異や関連性を評価し、その結果の信頼性を検証するための手法です。
- データの可視化:データの可視化には、グラフ、散布図、ヒストグラム、箱ひげ図、四分位数、クロス集計が含まれます。これらのツールを使って、データを視覚的に表現し、理解しやすくすることができます。
- 基本的なデータ分析手法:基本的なデータ分析手法には、相関分析、回帰分析(単回帰分析、重回帰分析)、ダミー変数、時系列分析(移動平均、季節要因)が含まれます。これらの手法は、データ間の関係を明らかにし、将来の傾向を予測するのに役立ちます。
- 応用的なデータ分析手法:応用的なデータ分析手法には、教師あり学習(決定木、ロジスティック回帰、SVM、ランダムフォレスト、自己回帰モデル)と教師なし学習(K平均法、主成分分析、アソシエーション分析)、強化学習(Q学習)が含まれます。これらの手法を使って、複雑なデータのパターンを発見し、予測精度を向上させることができます。
- 高度なデータ分析手法と最新技術:高度なデータ分析手法と最新技術には、ディープラーニング(ニューラルネットワーク、CNN、RNN、ディープQネットワーク)、生成モデル(生成敵対ネットワーク、変分オートエンコーダ)、ビッグデータ分析、テキストマイニング(自然言語処理、トピックモデル、固有表現抽出)が含まれます。これらの技術は、膨大なデータから有益な情報を抽出し、ビジネスや研究において重要な洞察を提供します。
段階的に学びを深め、高度な分析まで内容を理解できるようにしましょう。
コメント